2025. 6. 13.

LLM 기반의 RAG(Retrieval-Augmented Generation) 시스템이 각광받고 있는 지금, 핵심 요소로 떠오르는 것이 바로 문서 파싱(Document Parsing) 기술입니다. 구조화되지 않은 PDF, 스캔 이미지, 표, 보고서 등 다양한 문서들을 LLM이 이해할 수 있는 형태로 변환해야만 제대로 된 성능을 기대할 수 있기 때문입니다.
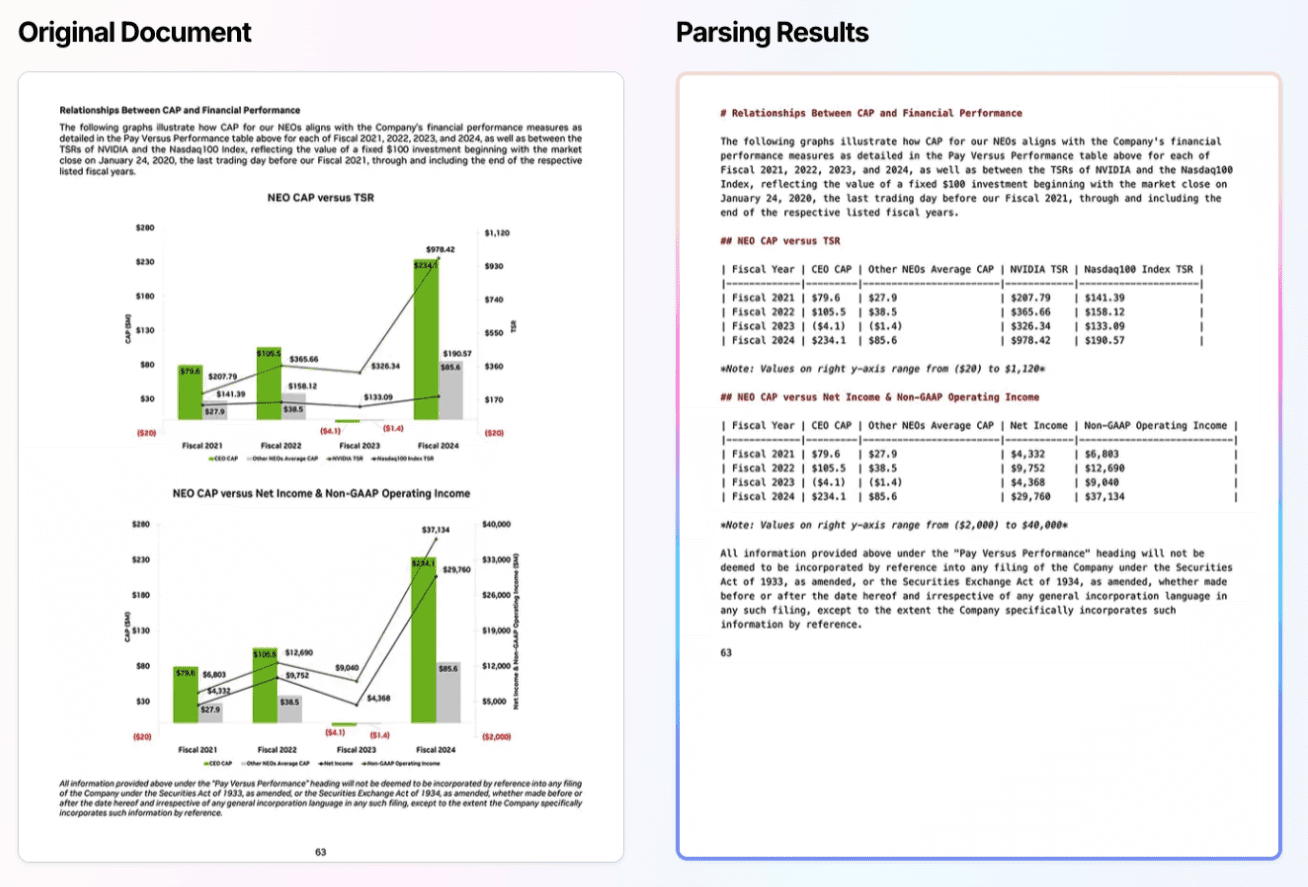
이번 글에서는 국내외에서 주목받고 있는 두 문서 파싱 툴, Upstage Document Parser와 LlamaParse를 비교 분석하며, 어떤 툴이 RAG 시스템에 더 적합한지 살펴보겠습니다.

Upstage Document Parser: 고속 정확도의 강자
Upstage Document Parser는 대한민국의 AI 스타트업 업스테이지(Upstage)에서 개발한 고성능 문서 분석 솔루션입니다.
핵심 특징
다양한 포맷 지원: PDF는 물론 스캔 이미지(JPEG, PNG), MS Office 문서(DOCX, PPTX, XLSX)까지 처리 가능합니다
정확한 레이아웃 분석: 단락, 표, 이미지, 차트 등을 정밀하게 인식합니다.
고속 처리 성능: 페이지당 평균 0.6초의 처리 속도로 대량 문서 처리에 적합합니다.
높은 정확도: TEDS 기준 93.48, TEDS-S 기준 94.16의 정밀도를 자랑합니다.
출력 포맷: HTML, Markdown 기반 구조화로 LLM의 문서 이해도 향상에 최적화되어 있습니다.
Supported file formats : JPEG, PNG, BMP, PDF, TIFF, HEIC, DOCX, PPTX, XLSX, HWP, HWPX
장점
속도와 정확도의 균형이 뛰어납니다.
복잡한 레이아웃의 기업용 보고서, 계약서에 최적화되어 있습니다.
AWS Marketplace에서도 제공되며, API 형태로 간편하게 사용할 수 있습니다.
가격 정책
페이지당 $ 0.01

LlamaParse: 유연성과 통합성의 강자
LlamaParse는 오픈소스 기반의 LlamaIndex 프로젝트에서 제공하는 문서 파싱 도구입니다. LLM과의 통합을 전제로 설계되어 있어 개발자 친화적인 기능이 풍부합니다.
핵심 특징
10가지 이상의 파일 포맷 지원: PDF, HTML, XML, PPTX, DOCX 등 포괄적인 문서 포맷 지원
분류 | 확장자 |
문서/프레젠테이션 | pdf, abw, cgm, cwk, doc(x/m), dot(m), hwp, key, lwp, mw, mcw, pages, pbd, ppt(x/m), pot(x/m), rtf, sda, sdd, sdp, sdw, sgl, sti, sxi, sxw, stw, sxg, txt, uof, uop, uot, vor, wpd, wps, xml, zabw, epub |
이미지 | jpg, jpeg, png, gif, bmp, svg, tiff, webp, web, htm, html |
스프레드시트 | xls(x/m/b/w), csv, dif, sylk/slk, prn, numbers, et, ods, fods, uos1/2, dbf, wk1–wk4, wks, 123, wq1/2, wb1–wb3, qpw, xlr, eth, tsv |
오디오 | mp3, mp4, mpeg, mpga, m4a, wav, webm (20MB 제한) |
고급 테이블 추출 기능: 복잡한 표 데이터를 정확하게 구조화합니다.
자연어 기반 파싱 제어: 자연어 명령으로 출력 포맷과 파싱 방식 지정 가능
JSON 포맷 지원: 원하는 정보만 골라 담기 쉬운 JSON 형태 출력 제공
다국어 지원: 다양한 언어를 인식할 수 있는 능력을 갖추고 있습니다.
LlamaIndex, LlamaCloud와의 통합: 완전한 RAG 파이프라인 구축이 가능합니다.
장점
유연한 파싱 규칙 제어로 다양한 커스터마이징 가능
오픈소스 기반으로 시작 비용이 낮습니다
RAG 파이프라인의 일부로 유기적 통합이 가능합니다
가격
10K Credits 무료 제공
Fast 모드: 페이지당 1 크레딧
Balanced 모드 (기본값): 페이지당 3 크레딧
Premium 모드: 페이지당 45 크레딧
RAG 시스템에서 문서 파서가 중요한 이유
RAG(Retrieval-Augmented Generation)는 정보를 검색하고, 이를 LLM에 주입하여 더욱 정확하고 신뢰성 있는 응답을 생성하는 방식입니다. 이때 검색 대상이 되는 문서의 구조화는 정확한 검색 결과와 생성 품질에 직결됩니다.
문서 파싱이 미치는 영향
표와 이미지의 인식 정확도는 LLM의 이해력에 직접 영향을 줍니다.
텍스트 분리와 재구성이 잘못되면 검색 인덱싱이 왜곡됩니다.
중복 또는 누락 정보는 생성 결과의 오류를 유발할 수 있습니다.
따라서 RAG 시스템을 제대로 활용하려면, 신뢰할 수 있는 문서 파싱 도구가 필수적입니다.
Upstage와 LlamaParse 비교: RAG에서의 적합성 분석
항목 | Upstage Document Parser | LlamaParse |
정확도 | 매우 높음 (TEDS 기준 93% 이상) | 표 및 텍스트 기준 정밀 추출 가능 |
처리 속도 | 빠름 (0.6초/페이지) | 중간 (클라우드 기반 처리 시간 존재) |
지원 문서 종류 | PDF, 이미지, DOCX, PPTX, XLSX 등 11개 유형 지원 | PDF, PPTX, DOCX, HTML, XML 등 112개 유형 지원 |
출력 포맷 | HTML, Markdown | JSON, HTML, Markdown |
통합성 | AWS, LangChain 등과 연동 | LlamaIndex, LlamaCloud와 완벽 통합 |
설정 유연성 | 자동 최적화 기반 | 사용자 정의 설정 자유도 높음 |
가격 정책 | $0.01/페이지 | 무료(제한적 사용 가능) |
어떤 경우 어떤 툴을 선택해야 할까?
Upstage Document Parser를 선택하면 좋은 경우
대량 문서를 빠르게 정확하게 변환해야 하는 기업 환경
복잡한 보고서, 계약서, 재무 데이터 등 레이아웃 중심 문서가 많은 경우
성능 안정성과 상용 API 연동이 중요한 경우
LlamaParse를 선택하면 좋은 경우
LLM 프로젝트를 개발하며 자유로운 파싱 규칙 제어가 필요한 경우
JSON 기반으로 세부 데이터를 구조화해 활용하고 싶은 경우
오픈소스를 활용한 유연한 확장성이 중요한 경우
성능 vs 유연성, 선택은 목적에 따라,
문서 파싱 도구의 선택은 단순한 기술 비교를 넘어서, 프로젝트의 목적과 요구사항에 따라 달라지는 결정입니다.
성능, 정확도, 안정성이 중요하다면 Upstage Document Parser가 더 적합합니다.
반대로 개발자 제어, 통합성, 커스터마이징이 중요하다면 LlamaParse가 좋은 선택이 될 수 있습니다.




